準備
状態集合、行動空間
状態集合をすべての状態からなる集合として定義し
S={s0,s1,s2,...,sN}
と表します。時間ステップごとに
S0,S1,...,St,...
とし、それぞれは (s0,s1,...) の中どれかを取ることになります。行動も同様に A として集合と、実際に取る値 (a0,a1,...) を定義しておきます。
報酬
状態の遷移に対する報酬は報酬関数として
Rt+1=fr(St,At,St+1)
で定まります。現在の状態 St から行動 At を選択して 1 ステップ後 St+1 に遷移したときに、どういった報酬が与えられるかということを意味しています。
どういった行動を取るか、どういった状態に遷移するか、などに依存するため、「最適な行動を取って最適な状態へ移動する」ということを報酬という数値で表現することができます。
収益
強化学習では得られる報酬を用いて方策を決めていきますが、報酬は行動の即時的な良さを示す指標であるため、長期的に見た場合の行動の良し悪しを評価する必要があります。
そこで収益と呼ば得れる考えを導入します。
収益は、ある期間で得られた報酬の累積和のことで、現時刻 t より将来の方向で和を取り
Gt=i=0∑TRt+1+i
で定義します。
ここまでの内容を図に表すと次のようになります。各時刻間の遷移は、マルコフ決定過程(Markov Decision Process: MDP)で定義されていて、どの時刻でどの状態を取るか、どの状態からどの状態へ遷移するかは確率的に記述されます。
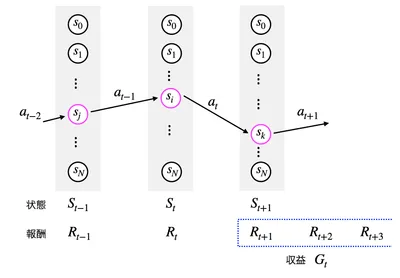 強化学習の基本用語のまとめ
強化学習の基本用語のまとめ
この図を見るとある状態からある状態へ遷移するときの行動 a と状態とが 1 対 1 で対応しているように錯覚してしまいますが、実際には行動 a を選択した際にどのような結果になるかは確率的です。そのため、行動 a を選択したときに状態 s から 状態 s′へ移動する確率は
P(s′∣s,a)
として遷移確率として表現されます。
状態価値
収益は、計算する区間の初期状態と将来の行動に依存する確率的に変動する値です。そこで状態を条件として収益の期待値を計算し、これを方策を定義する際の指標とします。それが状態価値関数(価値関数)です。
状態価値関数(価値関数)は、
Vπ(s)=Eπ[Gt∣St=s]
で定義されます。
初期状態 St=s のもとで、ある方策 π のもとで行動したときに得られる報酬の期待値が Vπ(s) です。これと同様に、
初期状態 St=s のもとで、ある方策 π′ のもとで行動したときに得られる報酬の期待値は Vπ′(s) です。
つまり、ある状態 s を固定したうえで方策の良し悪しを図る指標として扱うことができ
Vπ′(s)≶Vπ(s)
の大小関係で、どちらの方策がより良いかを評価できます。
行動価値
状態価値に加えて、行動も条件に加えた
Qπ(s,a)=Eπ[Gt∣St=s,At=a]
も考えることができ、同様に行動価値関数(行動価値)を定義することができます。
ベルマン方程式
強化学習の目的は最適な方策 π を探索することで、状態価値関数もしくは行動価値関数を用いることで現在の方策 π を評価することができるようになります。価値関数の値が大きくなるような方策を探索すればいいわけですが、例えば割引報酬和に関する価値関数を考えると
Vπ(s)=Eπ[Gt∣St=s]=Eπ[i=0∑∞γiRt+1+i∣St=s]
となり、この期待値を計算する必要が生じます。この式を正確に計算するには無限時間先までの計算(∑i=0∞ の計算)が必要になるため、そのままの形で計算することができません。
そこで価値関数を評価しやすい逐次的な処理に落とし込んだ関係式が、ベルマン方程式です。価値観数のt+1 の項と、t+2 以降の項とで計算を分離し、
まとめると次の関係式(ベルマン方程式)が導出されます。
Vπ(s)=a∈A∑π(a∣s)s′∈S∑P(s′∣s,a)(fr(s,a,s′)+γVπ(s′))
導出
状態価値関数は期待値の線形性を利用することで
Vπ(s)=Eπ[Gt∣St=s]=Eπ[Rt+1∣St=s]+Eπ[γRt+2+γ2Rt+3+...∣St=s]
とできます。
第一項目(t+1 の項)について、時刻 t から t+1 へ 1 ステップ移動するときの報酬の期待値を意味しています( St=s の条件付き期待値)。
画像「20251129-113439.png」が見つかりませんでした。
この期待値は上図にあるように、
- 状態 St=s で方策に従って行動 At=a を選択し(確率 π(a∣s))
- その選択した行動で状態 St+1=s′ に遷移する(確率 P(s′∣a,s)
という考え方をもとに計算をすると導出できます。そのため、 1 ステップ後に St+1=s′へ遷移するときに得られる報酬は
P(s′∣s,a)π(a∣s)×r(s,a,s′)
で表されます。行動 a と 状態s′ について全てのパターンを網羅することで、St=s の条件付き報酬の期待値、
Eπ[Rt+1∣St=s]=a∈A∑π(a∣s)s′∈S∑P(s′∣s,a)r(s,a,s′)
が計算できます。
第二項(t+2 以降の項)について、
Eπ[γRt+2+γ2Rt+3+...∣St=s]=a∈A∑π(a∣s)s′∈S∑P(s′∣s,a)Eπ[Rt+2+γRt+3+...∣St+1=s′]=a∈A∑π(a∣s)s′∈S∑P(s′∣s,a)Vπ(s′)
となり、これらをまとめることで、ベルマン方程式が導出できます。
書き換え
和の形のベルマン方程式から「条件付き期待値」の形に書き換えることができます。先程導出した状態価値関数のベルマン方程式を改めて書いておきます。
Vπ(s)=a∑π(a∣s)s′∑P(s′∣s,a)[R(s,a,s′)+γVπ(s′)](★)
ここで、記法を簡単にするため
f(s′,a):=R(s,a,s′)+γVπ(s′)
と定義しておきます。このとき (★) の右辺は
RHS of (★)=a∑π(a∣s)s′∑P(s′∣s,a)f(s′,a)=a∑s′∑π(a∣s)P(s′∣s,a)f(s′,a).
一方、MDP と方策の定義から
Pr(At=a,St+1=s′∣St=s)=π(a∣s)P(s′∣s,a)
が成り立ちます。したがって、上の式は
RHS of (★)=a∑s′∑Pr(At=a,St+1=s′∣St=s)f(s′,a)=E[f(St+1,At)St=s]
と、条件付き期待値の形に書き換えられます。定義に戻せば
f(St+1,At)=R(St,At,St+1)+γVπ(S_t+1)
なので、
Vπ(s)=E[Rt+1+γVπ(St+1)St=s]
という、期待値形式のベルマン方程式が得られます。
次回以降で
しかしベルマン方程式から直接価値関数を求めるには、状態遷移確率 P(s′∣s,a) が分かっている必要がありこの前提も一般的ではありません。そこで状態遷移確率の導出なしでベルマン方程式(価値関数)の値を計算する手法が考案されています。
ベルマン方程式を解くための具体的なアルゴリズムについては次回以降で議論していきたいと思います。
脚注
- こちらの形のほうが逐次的であることがより明確に理解できると思います