ML-Agent: Reinforcing LLM Agents for Autonomous Machine Learning Engineering
大規模言語モデル(LLM)ベースのエージェントの登場により、自律的な機械学習(ML)エンジニアリングの発展は大きく前進しています。しかし既存の多くの手法は、人手によるプロンプトエンジニアリングに強く依存しており、多様な実験経験に基づいて適応・最適化することができていません。この課題に対してこの研究では、LLM エージェントがオンライン強化学習(RL)を用いて ML タスク上でのインタラクティブな実験を通じて学習する Agentic ML を深堀りしました。
イントロダクション
近年の LLM ベースのエージェントの技術発展に伴い、自律的な機械学習エンジニアリング(Agentic ML)の実現が近づきつつあります。AIDEやSELA などはその一例です。ただ現在の手法では根本的な制約があり、プロンプトエンジニアリングに基づいているヒューリスティックなエージェントシステムである点です。
システムが自律的に試行錯誤を繰り返す「Agentic ML」の概要が図 1 です。この論文では初めて「learning-based agentic ML」というパラダイムを探究しています。LLM エージェントがオンライン強化学習(RL)を用いて、ML タスクにおけるタスク解決の軌跡から学習することが可能なシステムを想定しています。
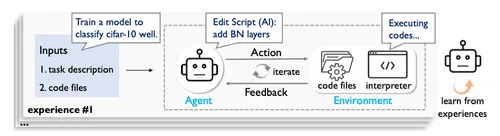
MDP としての実装
この研究では Agentic ML をマルコフ決定過程(MDP)として定式化しています。一般的な強化学習の枠組みをうまく機械学習パイプラインの試行錯誤の内容に落とし込んでいます。Agentic ML は各タイムステップにおいて、エージェントは行動(ex. モデルアーキテクチャに BN 層を追加する)を取り、環境からフィードバック(ex. コード実行結果やエラーメッセージ)を受け取ります。ステップ数の上限または時間制限に達するまで繰り返されます。この研究では、定義されているアクション空間に従います。

Agentic ML のコンセプト自体は比較的わかりやすい(一般的な強化学習の枠組み)ものの、自律的な機械学習のためにオンライン強化学習で訓練するにあたっては、いくつかの課題が存在します。
- 探索の網羅性の確保
- エージェントはエピソードをまたいで似たような行動を繰り返しがちであり、その結果、探索範囲が狭まり、新しい ML 解法を発見する能力が制限されてしまいます。→ exploration-enriched fine-tuning の導入
- 経験収集の遅さ
- ML の実験は数分から数時間かかる場合があり、オンライン RL の訓練に必要なデータ収集プロセスが大幅に遅くなってしまいます。→ Step-wise RL の導入
- 報酬設計の複雑さ
- Agentic ML では、実行結果やリソースエラーなど、さまざまな形のフィードバックが生じるため、エージェントを効果的に導く統一的な報酬関数を設計することが難しくなります。→ 専用の報酬の追加
そこでこの研究ではこれらの課題を解決するためのアイデアを盛り込んだシステムを作成しています。
Agentic ML フレームワーク
この研究で提案している Agentic ML トレーニングフレームワークは、自律的な機械学習のために LLM エージェントを訓練することを目的として設計されています。図 2 に示すように、本フレームワークは効率的な学習のための三つの主要なステップから構成されています。
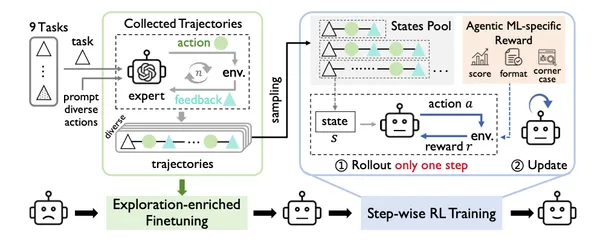
Extraporation-enriched fine-tuning
Agentic ML においては、探索の不足が自律的な機械学習ワークフローの妨げになります。エージェントはしばしばエピソード間で似たような行動(ex.小さなコード修正)を繰り返してしまい、その結果として探索範囲が狭くなり、新しいアーキテクチャや最適化戦略の発見が阻害されしまいます。この問題に対処するために、この研究では exploration-enriched fine-tuning を導入し、エージェントの行動多様性を高めます。
タスクについて、100 個以上の候補アイデア(ex. L1 もしくは L2 の重み正則化を追加する)を生成し、それらのペアワイズな埋め込み距離を計算します。例えば、
- アイデア 1: “add L1 weight regularization”
- アイデア 2: “add data augmentation with random crop”
- アイデア 3: “increase learning rate”
のように機械学習で用いる改善アイデアを用意しておき、その埋め込みベクトルを取得しておきます。そして、他のアイデアとの埋め込み距離が大きいもの(似通っていないもの)から 10 個の最も多様なアイデアを選択し、そのうち 1〜3 個をランダムにタスクのプロンプトへ含めます。このように高速に実行可能な ML タスクを利用することで、ML 実験に伴う計算コストの負担を軽減しています。つづいて、このエキスパート軌跡を用いて、LLM エージェントの方策 を教師ありファインチューニング(SFT) により訓練します。
この exploration-enriched fine-tuning によって、エージェントは Agentic ML ワークフローにおいて重要となる「フォーマットに適合した行動」を出力できるようになると同時に、多様な戦略も学習します。その結果、後続の強化学習フェーズにおける探索範囲が大きく広がることになります。
Step-wise RL paradigm
ML 実験は 1 回まわすのに「分〜時間」かかるので、PPO みたいな RL をそのまま「軌跡ごと」適用すると、1 本の軌跡サンプリングに数時間かかり実用的ではないです。
- エージェントが 1 ステップ分の行動(機械学習の改善アイデアを試す)を決める
- 実際に学習してその結果が返ってくる
- これをゴールまで繰り返すことで trajectory ができる
- この trajectory を使ってパラメーター更新
が一般的な強化学習の流れですが、機械学習の「学習時間」が長いためこの流れを何回もするのがなかなか難しいです。そこで著者らは、
「軌跡全体」ではなく「1 ステップの行動だけ」に分解して RL しよう
と発想を変えていて、これが step-wise RL です。
元々の目的関数
を状態分布に分解して書き直すと、次のようになります:
- :方策 のもとで時刻 に状態 にいる確率(状態分布)
- 状態分布は方策 と状態遷移確率 から再帰的に計算できます
- 今の方策 がどんな状態をどれくらいの頻度で訪れるかというもの
- :状態 で行動 を取ったときの報酬
です。 を得るには状態遷移を何度もシミュレートする必要があるのですが、ML 実験ではこのループが非常に高コストになってしまいます。そこで、
「オンラインで毎回 CIFAR-10 の学習を 1 エピソードずつまわすのではなく、先にエキスパートがいろいろ試した“スナップショット状態”を大量に保存しておき、あとは“その状態から 1 手だけ”を RL で学習させる」
という構造に変えるような、step-wise objective を導入しています。
流れとしては
- GPT-4o-mini みたいなそこそこ強いエージェントにいろんな ML タスクで実験させておく
- そのときの「途中状態」を全部ログに残しておく
- モデルのコード
- ハイパラ設定
- 直前の実行ログ(精度・損失・エラー)
- この「エキスパートがよく訪れた状態たち」の分布が です。
Agentic ML-specific reward
step-wise 強化学習(RL)パラダイムによって agentic ML における効率的な RL を可能にしたので、次の重要なステップは、多様なフィードバックを統一された意味のある報酬へと変換することです。検証精度や損失のような数値的な指標は、そのまま RL の報酬として扱うことができますが、コンパイルエラーやメモリ不足エラーのような非数値のフィードバックは、報酬関数の一貫性を保つために慎重に取り込む必要があります。
「Agentic ML のフィードバックを全部 0〜1 の数字にそろえるルール」です。
- フォーマットが壊れている・エラーを出した → 0
- 「その一手はダメ。ちゃんと動くコードを書いてください」というメッセージ。
- ファイルを眺めただけ・OOM で落ちた → 0.5 - 「悪くはないけれど、スコアも上がってない」という中立ポジション。 コードを編集して、スコアが良くなった → - 改善量が大きいほど 1 に近い報酬、小さいと 0.5 付近、悪化すると 0.5 未満へ。
最終的に で に圧縮することで、どのタスクでも「良くなったかどうか」を同じものさしで見られるようにしている、という設計になっています。
まとめ
論文を読んでいるだけだと「まぁ確かに」という発想が盛り込まれた強化学習の一般的な枠組みに見えますがやってみると難しそうなことばかりだと感じました。実装が公開されていないようなので(リンク)、このあたり取り組んでみたいなと思いました。