論文解説:Qwen3-VL Technical Paper
はじめに
2025年11月に出た Qwen3-VL Technical Report についてまとめます。長いコンテキスト長(最大 256K)、動画・高精度な推論、エージェント的ユースケースなどを盛り込んだアップデートが入っているモデルです。GitHub リポジトリも公開されています。
モデルアーキテクチャ
Qwen3-VL のモデル構造は以下の様になっています。
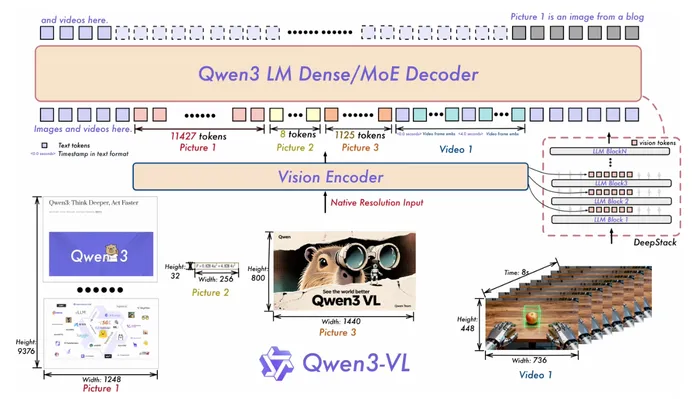
Large Language Model
Qwen3-VL全体は Vision Encoder + Merger + LLM Decoder の構成ですが、LLM Decoder の部分が Dense もしくは MoE の構成を取っています。 LLM Decoder 部分は Qwen3 のバックボーンを基盤として、3種類の dense モデル(Qwen3-VL-2B/4B/8B/32B)と、2種類の MoEモデル(Qwen3-VL-30B-A3B、Qwen3-VL-235B-A22B)として提供されています。
Vision Encoder
Vision Encoder 部分には SigLIP-2 アーキテクチャを採用していて、動的な解像度の変更に対応するような追加学習を行っています。解像度が変わると ViT の位置情報の扱いが難しくなるので、2D-RoPE と CoMP を用いた位置埋込みを行います。
MLP-based Vision Language Merger
ViT 系の Vision encoder では画像をパッチ分割して の格子状の特徴ベクトル列を出力するのですが、Qwen3-VL ではそれを の近傍ブロックごとにまとめて一つの visual token を作成します。 各パッチ特徴量を最終的に LLM のテキストトークンとして使用可能とするための役割を担っています。
Qwen3-VL の新規点
Qwen3 では以下の改良点が加えられています。
- 位置エンコーディングの強化
- クロスレイヤ融合のためのDeepStack
- 動画タイムスタンプ
Inteleaved MRoPE
Qwen2-VL ではマルチモーダル入力の位置情報を取り込むためにMRoPEを導入していました。埋め込み次元を temporal 、horizontal 、vertical の3つの部分空間に分解して、それぞれに異なる周波数を与える位置エンコーディング手法です。 この設計は長時間の動画に対する性能低下を引き起こすことがわかってきたため、Qwen3-VL では、 成分を交互に配置することで周波数割当を再設計した interleaved MRoPE を採用しました。
PE と RoPE について
PE(Positionalk Embedding)は、単語の位置情報を持たない Transformer に順序を持たせるための手法です。ここで
- 文章1:[A, B, C]
- 文章2:[C, B, A]
という単語を入れ替えた文章を考えてみます。Tom called Mary. と Mary called Tom のように、単語の入れ替えで文意が変わるため順序が重要であるケースを想定します。
文章1 [A, B, C] についてのAttention matrix は
であるので、Transformer の出力 は
となります。ここで文章2 [C, B, A] について考えてみます。同様の計算で、A と C とを入れ替えれば良く(埋め込み行列は同じものを使用するので)、
となります。見比べると [A, B, C] の時の出力の1行目と3行目とを入れ替えた出力になっているのが分かります。そのため、単語の入れ替え(順序の変更)によって出力の順序も入れ替わってはいるものの、生成される特徴ベクトルは同一のものになっていることが分かります。そのため Transformer はそのままでは位置情報を取り込めないため、位置埋め込み(positional embedding)を導入します。
Transformer 元論文では以下の項をトークン に足し合わせます。
Qwen3-VL の話に戻ると、位置埋込みではRoPE(Rotary Positional Embedding)と呼ばれる クエリ とキー に位置に応じた回転をかけることで相対位置の性質をもたせる手法を採用しています。
RoPE では2次元回転行列
を使用し、
として対角行列
を定義して、これをクエリとキーへ作用させます。ここでの がトークン位置です。クエリベクトルが埋込次元が 次元であるとすると
であるので、回転行列を掛けるために
として成分をペアずつで取り出して
のように計算させます。
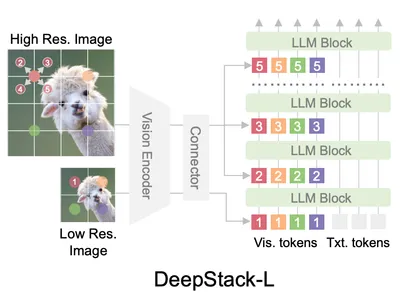
DeepStack
これまでの画像を扱うマルチモーダルモデルでは Vision Encoder の出力である visual tokens をそのまま LLM の入力層に連結していました。しかしこの方法では、入力層で扱うトークン数の爆発、計算コストの増加や高解像度で必要な情報の取り回しのしにくさなどがボトルネックになっている問題があります。
Qwen3-VL では DeepStack を採用し、ViT の中間層から取った特徴ベクトルを LLM Decoder の中間層の hidden state に直接加算することで visual token の相互作用を作りやすくし性能を上げる工夫をしています。
Video Timestamp
Qweb3-VL では動画の時間情報をうまく扱うために、タイムスタンプのトークンを埋め込む方式を取っています。Qwen2.5-VL では time-synchronized MRoPE で時間認識をしていたのですが
- 長尺動画で temporal position id が巨大かつ疎になり、長い時間文脈の理解が劣化
- 学習に 多様な fps に対する大量かつ一様なサンプリングが必要
となる問題がありました。Qwen3-VL では <3.0 seconds> のようなフォーマット済みの 文字列の タイムスタンプを prefix として付ける方式に変更しています。
学習について
Qwen3-VL の学習では pre-training と post-training の二種類の学習を行っています。
Pre-Training
Pre-training では4段階の学習を行っています。
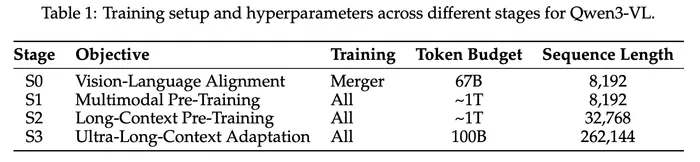
- Stage 0
- ステージ0では、MLP merge のパラメーターだけを学習して、Vision Encoder と LLM との間のドメインのギャップを埋めます(アライメント)。学習には 68B(670億)トークンのデータセットを用いて、シーケンス調 8192で実施します。
- Stage 1
- ステージ0の初期段階のアライメントが終了した後に、エンドツーエンドでの全パラメーターの学習に移行します。この段階では1T(1兆)トークンを使用して、シーケンス長は8192で学習します。
- Stage 2
- モデルの文脈処理能力を拡張するために、シーケンス長を 32,786 に増やして全パラメーターの学習を行います。大きな文脈に対応するために、テキストデータの比率を増やして学習を行います。また instruction データも取り込むことで複雑なタスクへの推論能力の獲得を狙っています。
- Stage 3
- 最終段階ではシーケンス長を 262,144 まで拡張して、コンテキストウィンドウの上限を最大化しています。
使用データ
- Image Caption and Interleaved Text-Image Data
- Web由来の中英中心の画像とテキストを集め、再キャプション用に調整した Qwen2.5-VL-32B でより詳細で流暢な説明に作り直したものを使用しています(属性・空間配置・文脈などを補強)。
- Knowledge
- 動物・植物・ランドマーク・食べ物・日用品(車/家電/衣類など)を含む「エンティティ中心」の大規模データを構築し、現実/架空の概念理解を強化します。
- OCR, Document Parsing and Long Document Understanding
- 社内収集の約 3,000万 サンプルを、OCR特化モデルの疑似ラベル+Qwen2.5-VLの精緻化で再注釈(人手なし)。さらに追加で 29言語 を拡張し、多言語OCRデータも大規模化しています。
- Grounding and Counting
- COCO / Objects365 / OpenImages / RefCOCO系などを統合し、未ラベル画像から Qwen2.5-VL と Grounding DINO などで候補抽出→局在→品質評価で大規模合成も行っています。
- Spatial Understanding and 3D Recognition
- 単なる位置特定を超え、物体間関係(例:左/右)、アフォーダンス(graspable等)、行動計画を要する質問を含むデータで、相対参照による関係推論を鍛えます。
- 単眼画像+参照表現+9-DoF 3D bbox(JSON) をVQA形式に再構成し、ノイズ/遮蔽を除外、Omni3Dに倣い仮想カメラ座標系へ統一することで3D参照表現も詳細キャプションで強化しています。
- Code
- Qwen3 / Qwen3-Coderの大規模コードコーパスを再利用し、言語・領域・タスク多様性で基礎を作ります。
- Video
- 時間方向の理解、空間関係の精密知覚、超長尺の要約を強化します。
- STEM
- コード生成で幾何図形を描画し、点グラウンディング 100万、知覚寄りVQA 200万、さらに検証付き2段階キャプションで 600万 の図表キャプションを作ります。
- Agent
- デスクトップ/モバイル/Web横断の大規模データで、要素説明・dense captioning・dense grounding等を作り、さらに自己進化型の軌跡生成+人手監査でマルチステップ遂行を鍛えます。
- Function calling:画像付きで「ユーザ要求→関数定義→呼び出し→応答」までの軌跡を合成し、形式エラー等でフィルタしながら反復生成する。
- Search:画像検索・テキスト検索を含む事実照会軌跡を集め、未知/ロングテール概念に対して検索で知識統合する行動を学ばせる。
Post-Training
使用データ
- Supervised Fine tuning Data(指示追従・実用タスクの土台)
- 現実の幅広いユースケースを解けるようにする(Qwen2.5-VLの能力を土台に機能領域を拡張)。
- 身体性(embodied)を意識した空間推論
- 画像に根差した細粒度推論(image-grounded reasoning)
- 動画での時空間グラウンディング(追跡など)
- 数百ページ級の長文技術文書の理解
- 規模・構成
- 約1,200,000 サンプル。
- 1-turn / multi-turn を混在し、単一画像〜複数画像など「現実の会話ダイナミクス」を模擬。
- 現実の幅広いユースケースを解けるようにする(Qwen2.5-VLの能力を土台に機能領域を拡張)。
- Long-CoT Cold Start Data(Thinkingモデルの“推論起動”用)
- 長い Chain-of-Thought を安定して出せるよう、難問中心の cold start データでブートストラップ。
- Strong-to-Weak Distillation(蒸留)
- 軽量モデルの性能を上げるため、Qwen3と同様の Strong-to-Weak 蒸留を適用。
- Reinforcement Learning(RL)
- 数学、コーディング、論理推論、visual grounding、視覚パズルなど。
- いずれも ルールや実行器で決定的に検証できるよう設計。
- 報酬設計
- タスク共通のインフラ(前処理、ユーティリティ、reward manager)を用意し、コアはタスク別。
- フォーマットはタスク別プロンプトで誘導し、明示的なフォーマット報酬には依存しない。
- prompt と異なる言語で返す場合はペナルティ(code-switching抑制)。
- RLアルゴリズムとしてSAPOを採用。
- General Reinforcement Learning(汎用性・頑健性・好み整合)
- 一般化能力と運用上の頑健性を上げる。
- SFTで得たタスク群(VQA、caption、OCR、文書解析、grounding、時計認識など)を包含する multi-task RL。
- Thinking with Images(視覚エージェント化:tool統合)
- 既存研究の「thinking with images」方針に触発され、2段階で agentic 能力を付与。