価値関数
強化学習において価値関数(value function)は、状態もしくは状態−行動ペアの関数で、その状態もしくは状態-行動がどれだけ「良い」かを推定するための関数です。
強化学習における「良さ」とは、将来的に受け取れる報酬(期待収益; expected return)によって定義されます。
状態価値関数
方策 π とは、各状態 s∈S と行動 a∈A(s) に対して、その状態 s で行動 a を選ぶ確率 π(a∣s) を与える写像であることを思い出してください。方策 π の下での状態価値関数 vπ(s) は、状態 s から開始し、その後は π に従うときの期待収益として次のように定義されます。
vπ(s)=Eπ[Gt∣St=s]=Eπ[k=0∑∞γkRt+k+1 St=s]
ここで Eπ[⋅] は、エージェントが方策 π に従うという条件の下での確率変数の期待値を表し、t は任意の時刻です。
行動価値関数
方策 π の下で状態 s において行動 a を取ることの価値 qπ(s,a) を、状態 s から開始し、行動 a を取り、その後は方策 π に従うときの期待収益として定義します
qπ(s,a)=Eπ[Gt∣St=s, At=a]=Eπ[k=0∑∞γkRt+k+1 St=s, At=a].
関数 qπ を、方策 π の行動価値関数(action-value function)と呼びます。
ベルマン方程式
準備(広義の遷移確率)
状態の遷移確率を次のように、状態と報酬との同時確率で定義します。
p(s′,r∣s,a)
教科書によっては遷移確率を p(s′∣s,a) として定義していますが、以下ではr が含まれていることの説明をしておきます。
一般的には、同じ s,a,s′ に対しての報酬
r(s,a,s′)
は確率的にブレる状況が生じます。例えば測定誤差や乱数ノイズなどが生じるケースや、その瞬間の市場価格・需要・天候などで利益(報酬)が変わる様な在庫補充、電力取引、配車であったりなどのケースが挙げられます。そのため、以下のように s′ だけでなく r も含んだ 同時確率 の形式で定義しておきます。
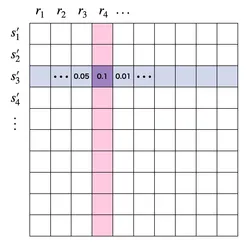 同じ状態に対して得られる報酬が確率的にブレる場合、同時確率として表すことになる。
同じ状態に対して得られる報酬が確率的にブレる場合、同時確率として表すことになる。
状態価値関数に対する導出
価値関数の基本的な性質は、特定の再帰関係を満たすことです。任意の方策 π と任意の状態 s に対して、次の条件が成り立ちます。
vπ(s)=Eπ[Gt∣St=s]=Eπ[k=0∑∞γkRt+k+1 St=s]=Eπ[Rt+1+γk=0∑∞γkRt+k+2 St=s]=Eπ[Rt+1∣St=s]+Eπ[γk=0∑∞γkRt+k+2 St=s]
ここで1ステップ遷移あとの状態を St+1=s′ とすると、方策 π による行動の選択と遷移確率とを考慮すると第一項は
Eπ[Rt+1∣St=s]=a∑s′,r∑(π(a∣s)p(s′,r∣s,a)×r)
と期待値の計算を行うことができます。第二項の計算も、1ステップ進めたあとの期待値に直すと
Eπ[Rt+1∣St=s]=a∑s′,r∑(π(a∣s)p(s′,r∣s,a)×Eπ[γk=0∑∞γkRt+k+2 St+1=s′])=a∑s′,r∑(π(a∣s)p(s′,r∣s,a)×vπ(s′))
と計算できます。これらを合わせると
vπ(s)=a∑π(a∣s)s′,r∑p(s′,r∣s,a)[r+γvπ(s′)]
として再帰的な関係式を導出することができます。この関係式が、価値関数 vπ に対するベルマン方程式(Bellman equation)です。
行動価値関数に対する導出
行動価値関数 qπ(s,a) に対してもベルマン方程式を導出できます。
qπ(s,a)=Eπ[Gt∣St=s, At=a]=Eπ[k=0∑∞γkRt+k+1 St=s, At=a]=Eπ[Rt+1+γk=0∑∞γkRt+k+2 St=s, At=a]=Eπ[Rt+1∣St=s, At=a]+γEπ[k=0∑∞γkRt+k+2 St=s, At=a]
第一項は
Eπ[Rt+1∣St=s, At=a]=s′,r∑p(s′,r∣s,a)r
と書けます。第二項も同様に、
Eπ[k=0∑∞γkRt+k+2 St=s, At=a]=s′,r∑p(s′,r∣s,a)Eπ[k=0∑∞γkRt+k+2 St+1=s′, Rt+1=r, St=s, At=a]=s′,r∑p(s′,r∣s,a)Eπ[k=0∑∞γkRt+k+2 St+1=s′]=s′,r∑p(s′,r∣s,a)Eπ[Gt+1 ∣ St+1=s′]=s′,r∑p(s′,r∣s,a)vπ(s′)
と書けます。これらを合わせることで、
qπ(s,a)=s′,r∑p(s′,r∣s,a)[r+γvπ(s′)]
と、状態価値関数に対するベルマン方程式を導出することができました。