結局どれを使う?SD1.5・SDXL・FLUXと派生モデルの選び方(実務版)
画像生成を始めると、まず「どのモデルを使うか」で迷います。ところが実際は、SD1.5やSDXLのようなベースモデルの世代差だけでなく、Ponyのような巨大ファインチューン、A1111/ComfyUI/diffusersといった運用スタック、LoRAの作りやすさ・効きやすさ、そして商用可否を左右するライセンスまでが一体で効いてきます。この記事では、SD1.5 / SDXL / FLUX をベースモデルとして整理し、派生チェックポイントを含めて「どれを選ぶと、何が楽で、どこで詰まるか」を実務目線で俯瞰します。目的別の選び方ができる状態をゴールにします。
この記事の狙い
画像生成の「主要モデル」と一口に言っても、実際には
- ベースモデルの世代(SD1.5 / SDXL / FLUX)
- 派生チェックポイント(Pony のような巨大ファインチューン)
- 運用スタック(A1111 / ComfyUI / diffusers)
- LoRA など拡張の作りやすさ、効きやすさ
- ライセンス(特に商用)
が絡み合って、最適解が変わります。この記事では、SD1.5 / SDXL / Pony / FLUX を「技術・実務」視点で整理します。
| 系統 | 代表 | 解像度 | 得意 | 苦手/注意 | 典型用途 |
|---|---|---|---|---|---|
| SD1.x | SD1.5 | 512 | 軽い、資産が膨大、LoRA運用が枯れてる | 高解像・手足・文字は工夫が必要 | LoRA量産、検証速度重視、既存資産活用 |
| SDXL | SDXL 1.0 / 実写系XL | 1024 | 破綻が減りやすい、全体の質が高い | LoRA学習の設計ポイントが増える | 実写/高品位、1枚の完成度を取りに行く |
| SDXL派生 | Pony Diffusion (v6 XLなど) | 1024 | キャラ/アニメ/タグ文化、強い表現力 | “Pony流”の作法がある、用途が偏る | キャラ、スタイル、コミュニティワークフロー活用 |
| FLUX | FLUX.1 schnell / dev | 高品質(モデル系統が異なる) | プロンプト追随・品質が高い傾向 | VRAM/環境、ライセンス差が大きい | 画質最優先、次世代系の試行 |
ベースモデル
SD1.5
Stable Diffusion v1-5(SD1.5) は「潜在拡散(Latent Diffusion)」で、VAEで潜在空間に落として拡散を回す設計です。学習・推論の前提が 512px(近辺)に強く、運用資産(LoRA、ControlNet、ワークフロー、Tips)が最も豊富です。実務の勘所としては
- とにかく軽いので、試行回数が容易
- LoRAの学習・適用の “定石” が広く共有されている
- 高解像や細部は「Hires.fix / アップスケール / リファイン」など工程で補うことが多い
などの取り回しのしやすさなどが特徴になります。
SD1.5 系のコア設計(VAEで潜在空間へ圧縮して拡散)に関する論文は High-Resolution Image Synthesis with Latent Diffusion Models(Rombach et al.) です。 この図は Stable Diffusion などの「潜在拡散モデル」の流れを示しています。まず画像 を VAE エンコーダ で潜在表現 に圧縮し、潜在空間でノイズを加える拡散過程と、その逆にノイズを除去する過程を行います。ノイズ除去は Denoising U-Net が担当し、複数ステップを繰り返して (ほぼノイズ)から を得ます。右側のテキストなどの条件は cross-attention の として U-Net に注入され、生成内容を誘導します。最後に VAE デコーダ で を画像 に復元します。
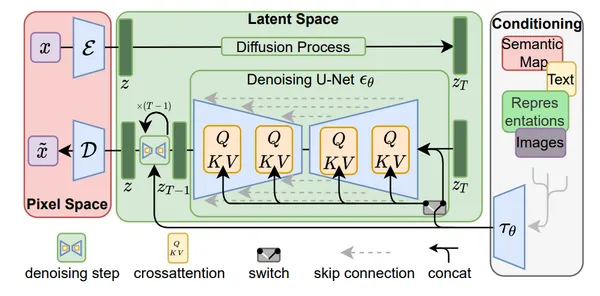
LoRA などの学習について
SD1.5 の LoRA 学習で通常更新するのは、図の中央にある Denoising U-Net の重みです。特に多いのは、条件(テキスト)を取り込む cross-attention 部分で、(および出力投影)を作る線形層に LoRA を差し込み、低ランクの追加重みだけを学習します。これにより、プロンプトに反応して人物やスタイルを呼び出しやすくなります。一方、VAE は通常固定で、Text Encoder も学習しない設定が一般的です。
SDXL
Stable Diffusion XL(SDXL)は SD1.5 と同じく「潜在拡散(Latent Diffusion)」の枠組みですが、より高解像度・高忠実度を狙って設計が強化された世代です。前提解像度は が中心で、学習時に複数アスペクト比を扱えるようにしつつ、U-Net を大きくし、さらに2つのテキストエンコーダを用いる点が大きな違いです。加えて、生成後半の画作りを担う Refiner(後段モデル)を導入し、ベースで作った画像を img2img 的に磨き上げて視覚品質を上げる構成も提案されています。
実務の勘所としては、次の特徴が扱いを左右します。
- 前提が なので、SD1.5より VRAM と計算が重くなりやすい
- 2つのテキストエンコーダにより、プロンプト追随(とくに記述量)で強みが出やすい
- Refiner を併用すると「最後の仕上げ」が効く一方、運用(工程)が増えます
- ベースモデル(SDXL)自体の表現力が高いので、LoRA の学習設計が結果を左右しやすいです
SDXL の設計をまとめた論文は SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis(Podell et al.) です。論文では、モデル規模の拡大(注意ブロック増加や cross-attention 文脈拡張)と、2つ目のテキストエンコーダ導入、複数の conditioning 設計、アスペクト比を跨いだ学習、さらに Refiner による品質向上が説明されています。
処理の流れ自体は SD1.5 と同じです。違いは主に「条件付け(conditioning)の強化」と「U-Net の大型化」です。SDXL では、テキスト条件 が 1本ではなく 2本になり、それが U-Net 内の cross-attention()に注入されます。また、生成の後半を Refiner に引き継ぐことで、低ノイズ領域でのディテールや質感の調整を強める設計になっています。
SDXL base では OpenCLIP ViT-bigG(G) と CLIP ViT-L(L) の2つの事前学習済みテキストエンコーダを使うことで、テキスト条件を強める設計になっています。両エンコーダの“後ろから2層目(penultimate)”の出力をチャネル方向に結合して、U-Net の cross-attention に渡す設計となっています。これにより、片方だけよりも テキスト‐画像アラインメント(指示の守りやすさ)と表現力が上がる、という狙いです。さらに SDXL では、OpenCLIP 側の pooled text embedding も別経路の条件として使う、と整理されることがあります。
実務的な理解としては、「G は自然文(文章)に強く、L はタグ列(カンマ区切り)に強い傾向があるので、両方を持つことでプロンプトの解釈の幅を広げる」と考えると分かりやすいです(この性質差はコミュニティ実験・議論でもよく言及されています)。
LoRA などの学習について
SDXL の LoRA 学習で通常更新するのは、図の中央にある Denoising U-Net の重みです。特に、条件(テキスト)を取り込む cross-attention 部分( と出力投影)に LoRA を差し込み、低ランクの追加重みのみを学習する構成が基本になります。
ただし SDXL はテキストエンコーダが 2本あるため、人物同一性やトリガー語の効きを強めたい場合には、U-Net に加えて Text Encoder 側(2本のうち片方または両方)も 低い学習率で学習する運用が選択肢になります。SD1.5 の「UNet だけでだいたい効く」感覚よりも、SDXL では「どこまで TE を触るか」が成果に影響しやすい点が実務上の差になります。なお VAE は SD1.5 と同様、通常は固定で運用します。
FLUX(FLUX.1 / FLUX.2)
FLUX は Stable Diffusion の開発者が立ち上げた Black Forest Labs が公開しているベースモデル系のファミリーです。現在FLUXは FLUX.1 と FLUX.2 が存在しており、別アーキテクチャとして扱われます。FLUX.1 は 12B 規模の rectified flow transformer を中核に、text-to-image を主軸として schnell/dev など用途別バリエーションが整備されています。一方 FLUX.2 は事前学習から刷新された新系統で、dev は 32B 規模とされ、生成だけでなく編集や制作現場向けの制御性をより強く押し出しています。
FLUX.1 は3種類のモデルが提供されています。
- FLUX.1 [schnell]:高速・少ステップ向け。検証を回す用途に強く、軽快に回せます(HuggingFace)
- FLUX.1 [dev]:品質重視の開発版。非商用アプリ向けのウェイトで、pro の蒸留版です(HuggingFace)
- FLUX.1 [pro]:API提供の商用枠。モデル管理や最適化は提供側に任せて利用できる
FLUX.2 は5種類のモデルが提供されています。
- FLUX.2 dev:オープンウェイト版。研究・ローカル評価向けで計算は重めです(HuggingFace)
- FLUX.2 klein:軽量枠。速度とコスト重視で、たくさん試作したい用途向け
- FLUX.2 flex:API向け。品質と自由度のバランスが良く検証〜運用向け
- FLUX.2 pro:API向け本番枠。高品位生成と参照画像を使う制御に強い
- FLUX.2 max:API向け最高品質枠。コストは上がりますが最終納品の追い込み向け
ファインチューン系モデル
Pony(Pony Diffusion)
Pony Diffusionは、PurpleSmartAIがSDXLをベースに「My Little Pony」系の生成を起点として発展させた大規模ファインチューン群です。学習データを美的スコアで整備し、captionとタグを併用する方針が広まり、V6 XLでは約260万枚規模・safe/questionable/explicitの比率調整などを明示して公開されました。配布はCivitAIやHugging Faceに広がり、クレジット表記や商用条件を含む独自ライセンス運用も話題になりました。score/source/ratingといった独自タグ文化が定着し、派生マージやLoRA生態系を生み、用途がポニー専用から広いキャラ生成へ拡張していきました。
Pony(Pony Diffusion)は、一般に「Pony Diffusion V6 XL」などで知られる SDXL ベースの大規模ファインチューン系モデルです。用途としては実写の王道というより、キャラクター表現(アニメ、カートゥーン、ファーリー等)に強く、コミュニティで蓄積された“Pony流のプロンプト作法”とセットで運用されることが多いです。特に特徴的なのは、学習データに由来する score タグや source / rating タグといった、Pony固有のタグ文化がプロンプト設計に強く影響する点です。
実務の勘所としては、次の特徴が扱いを左右します。
- SDXL 派生なので、前提解像度は が基本になり、SD1.5より重くなりやすいです
- 「score_9, score_8_up, …」のような score 系タグを入れることで出力傾向が安定しやすいです
- 「source_anime / source_cartoon / source_furry」などで画風の方向を指定しやすいです
- 「rating_safe / rating_questionable / rating_explicit」などの rating タグで出力の方向が変わる場合があります
- “masterpiece” のような汎用クオリティタグは不要、という流儀で紹介されることもあります
代表的な Pony モデルは
などが挙げられます。
Illustrious
Illustrious は SDXL 系のイラスト特化モデルで、実写よりもイラスト寄りの質感や線の表現に焦点を当てた系統で、コミュニティでは SDXL アニメ/イラスト系モデルの有力候補として参照されることがあります。
- SDXL 系なので、前提解像度は が基本になり、SD1.5より重くなりやすいです
- タグ列(カンマ区切り)やプロンプトの流儀は、SDXLアニメ系の慣習に寄ることが多いです
- ベースの SDXL と比べて「イラスト寄り」に分布が寄っているため、実写の一貫性や質感は用途次第で相性が出ます
- LoRA 学習は SDXL と同様に U-Net の cross-attention()周りを主対象にする設計が基本になり、人物同一性を詰める場合は Text Encoder の扱いも含めて設計が効いてきます
さいごに
SD1.5 は資産と軽さで今なお強い検証基盤だと思いますが、やはり SDXL の解像度の高さは捨て難いです。FLUX は系統が異なる次世代ベースとして魅力がある一方、環境要件とライセンスの取り回しがユーザーによってはネックになるかもしれません。今から画像生成を始めるのであればSDXLをベースとして進めるのが良いかとは思います。ただしまだまだ情報が不足している部分もあるため、適宜SD1.5の環境も用いるのがいいかもしれません。